Designing a GPU-Accelerated Communication Layer for Efficient Fluid-Structure Interaction Computations on Heterogeneous Systems
SC24: International Conference for High Performance Computing, Networking, Storage and Analysis
Aristotle Martin, Geng Liu, Balint Joo, Runxin Wu, Mohammed Shihab Kabir, Erik W. Draeger, and Amanda Randles
Summary
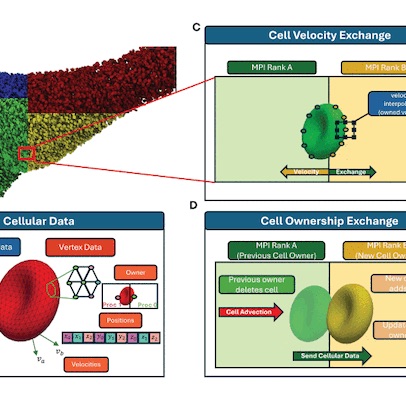
As biological research demands simulations with increasingly larger cell counts, optimizing these models for largescale deployment on heterogeneous supercomputing resources becomes crucial. This requires the redesign of fluid-structure interaction tasks written around distributed data structures built for CPU-based systems, where design flexibility and overall memory footprint are key considerations, to instead be performant on CPU-GPU machines. This paper describes the trade-offs of offloading communication tasks to the GPUs and the corresponding changes to the underlying data structures required, along with new algorithms that significantly reduce time-to-solution. At scale performance of our GPU implementation is evaluated on the Polaris and Frontier leadership systems. Real-world workloads involving millions of deformable cells are evaluated. We analyze the competing factors that come into play when designing a communication layer for a fluid-structure interaction code, including code efficiency, complexity, and GPU memory demands, and offer advice to other high performance computing applications facing similar decisions.
Citation
Martin, Aristotle, et al. “Designing a GPU-Accelerated Communication Layer for Efficient Fluid-Structure Interaction Computations on Heterogeneous Systems.” SC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024.