Lead PI:
Center Researchers:
Collaborating Partners
- Geng Liu, Saumil Patel, Silvio Rizzi, Victor Mateevitsi, and Joseph Insley from Argonne National Laboratory
- Balint Joo, Seyong Lee, and Jeffrey Vetter from Oak Ridge National Laboratory
- Erik Draeger from Lawrence Livermore National Laboratory
The Challenge
As high performance computing (HPC) platforms continue to evolve, large-scale simulations face critical challenges:
- Portability across diverse GPU architectures:
Modern supercomputers incorporate heterogeneous GPU architectures, such as NVIDIA A100 GPUs on Polaris and AMD MI250X GPUs on Frontier. While compute unified device architecture (CUDA) provides mature optimizations for NVIDIA hardware, maintaining comparable performance on AMD GPUs requires translation of code to heterogeneous-computing interface for portability (HIP), exposing differences in memory hierarchy, cache behavior, and compute unit configurations. Achieving performance parity across these platforms remains a non-trivial task.
- Communication bottlenecks in hybrid CPU-GPU systems:
Traditionally, distributed simulations rely on CPU-driven communication tasks with significant host-to-device data transfers. These transfers result in substantial latency penalties, especially as simulation sizes scale to tens of millions of elements across multiple nodes. Host-side operations, such as cell ownership updates and message buffer management, introduce further overhead that limits scalability.
- Scalability at extreme node counts:
In large-scale simulations, such as fluid-structure interaction (FSI) models involving millions of red blood cells, inter-node communication can dominate the runtime. Efficient communication strategies and load balancing become essential to ensure that the compute resources, particularly GPUs, are fully utilized.
Our Solution
We addressed these challenges through a combination of performance portability strategies and GPU-optimized communication techniques, creating a unified solution that delivers significant speedups and scalability across both NVIDIA and AMD platforms.
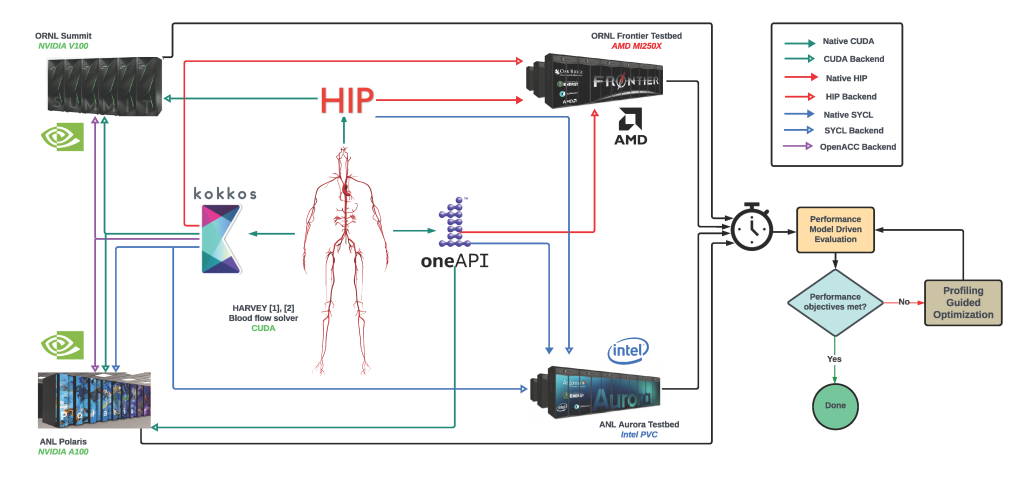
- Unified portability through CUDA and HIP:
We adopted a dual programming approach to maintain performance portability. CUDA kernels were ported to HIP to ensure compatibility with AMD GPUs while preserving the optimized structure for NVIDIA platforms. The solution includes:
- HIP portability layer: A direct translation of GPU kernels from CUDA to HIP enables execution on both NVIDIA A100 (Polaris) and AMD MI250X (Frontier) systems.
- Platform-specific optimization: We restructured memory access patterns to mitigate cache size differences and optimized kernel execution paths for AMD’s architecture.
The result is a unified codebase that achieves strong performance across heterogeneous platforms, providing a scalable solution for future GPU hardware.
- Fully GPU-Resident communication layer:
To eliminate host-device bottlenecks, we re-engineered the communication layer to operate entirely on the GPU. Key optimizations include:
- GPU-aware MPI: Using GPU-aware MPI libraries, we enabled direct device-to-device communication, bypassing the need for costly host transfers.
- Efficient communication tables: Device-side communication tables were pre-allocated and updated using parallel prefix sums, removing host-side overhead and enabling asynchronous operations.
- Contiguous buffer management: Sparse communication buffers were replaced with contiguous structures in GPU memory to optimize transfer efficiency and reduce latency.
- Parallelized cell management: Operations like ownership updates, vertex exchanges, and deletion routines were fully parallelized on the GPU, leveraging efficient compaction techniques to maximize memory usage and reduce communication overhead.
- Scalability for large simulations:
Our optimizations were tested on large-scale FSI simulations involving up to 32 million red blood cells across hundreds of nodes. The fully GPU-optimized communication layer, combined with efficient load balancing, demonstrated excellent weak scaling performance:
- On Polaris (NVIDIA A100 GPUs): The optimized communication layer delivered up to 6x speedup over baseline CPU-driven implementations.
- On Frontier (AMD MI250X GPUs): Despite architectural differences, the HIP-based solution achieved up to 4x speedup, highlighting the effectiveness of our portability strategy.
By ensuring that communication tasks remained GPU-resident and removing host-device dependencies, we achieved consistent performance improvements at scale.
This work presents a unified solution to address the challenges of portability and communication bottlenecks in GPU-accelerated simulations. The dual CUDA-HIP programming approach ensures that the codebase runs efficiently across NVIDIA and AMD platforms, while the fully GPU-resident communication layer eliminates host-induced overheads. These optimizations collectively enable large-scale, high-fidelity simulations with excellent weak scaling performance.